业界 来源:TDengine 2022-05-28 20:38:04 阅读:1446
TDengine Database开源项目里已经包含了性能对比测试的工具源代码。https://github.com/taosdata/TDengine/tests/comparisonTest,并基于这个开源的测试工具开展了TDengine和InfluxDB对比测试,TDengine和OpenTSDB对比测试,TDengine和Cassandra对比测试等一系列性能对比测试。为了更客观的对比TDengine和其他时序数据库(Time-Series Database)的性能差异,本项目采用由InfluxDB团队开源的性能对比测试工具来进行对比测试,相同的数据产生器,相同的测试用例,相同的测试方法,以保证测试的客观公平。
本项目是基于InfluxDB发布的一个性能对比测试项目的基础上开发的。数据产生模块可以模拟Devops场景下多台服务器产生大量监控数据。数据写入程序可以根据不同的数据库格式,将产生的模拟数据以不同的格式写入到不同数据库里,以测试写入性能。查询模块以相同的查询类型产生相同的查询任务,以各数据库自己的格式进行查询,并统计查询消耗的时间,来测试查询性能。
为了让测试过程更简单,本测试采用Docker容器方式来测试,所有被测的数据库都以容器的方式,从Dockerhub拉取下来,并设定固定的IP地址运行,便于脚本执行。容器镜像都是公开发布的,能保证测试的公平公正。
本测试项目目前支持以下时序数据库的对比测试
InfluxDB
TDengine
本项目的Github链接:https://github.com/liu0x54/timeseriesdatabase-comparisons
为了开展测试,需要准备以下条件
一台Linux服务器,包含10GB的空闲硬盘空间,用于存储产生的测试数据。因为测试模拟数据先生成并写入硬盘文件,由数据加载程序从文件中读取一条条的数据写入语句,写入时序数据库。这种方式能够将数据产生过程中的性能差异排除。
root权限。测试过程需要用root权限来安装一个TDengine的客户端驱动,用于TDengine数据加载程序的调用。TDengine数据写入采用Go语言调用C语言连接器的方式。
先从下载地址下载我们已经制作好的测试工具包,解压到本地。
tar -zxf tsdbcompare.tar.gz
解压后的目录结构如下:
bin 目录里是提前编译好的可执行文件,包括数据产生,数据加载,查询产生和查询加载。提前编译好方便大家下载即可用;如果有兴趣的同学也可以自己从源文件编译。源文件位于cmd下面的各个子目录里。可以自行编译后替换bin目录的文件。
config 目录里是TDengine写入数据需要用到的schema配置文件,模拟数据产生的数据通过schema配置里的信息可以知道该往哪个表里存。
data 目录是用来存储测试过程中产生的数据文件。本测试采用先产生模拟数据,并将模拟数据按各数据库的写入格式写到文件里,再用加载程序从文件里读取按格式写好的语句往各数据库里加载的方式来开展测试。这样的方法,能够将原始数据转换成不同的格式的过程带来的差异进行屏蔽,更纯粹的对比数据库的写入性能。
prepare.sh 是用来准备测试环境的脚本,包含三部分,1.安装docker程序,2.安装TDengine的客户端,3.拉取InfluxDB和TDengine的Docker镜像。
#!/bin/bash
set-x
#install docker
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
#install tdengine client
tar -zxf TDengine-client-1.6.4.5.tar.gz
cd TDengine-client-1.6.4.5
./install_client.sh
cd ..
#pull influxdb and tdengine docker images
docker pull influxdb
docker pull tdengine/tdengine:v1.6.4.5.c
如果目标系统上已经安装了docker程序,就不用执行这个prepare.sh脚本了,可以直接按脚本里的第二、三部分去安装TDengine Client和拉取对应的Docker镜像。
在上面的步骤都执行完成,并确认成功后,可以开展测试工作了。
注意事项:
1.如果系统里已经安装了其他版本的TDengine,请先卸载TDengine,否则会因为客户端和服务端版本不一致导致测试数据加载程序连接TDengine失败。
2.要确认TDengine-client-1.6.4.5.tar.gz安装成功,因为本次测试的加载和查询程序都是用的这个版本的client端lib库进行编译的,如果版本不匹配,会导致连接TDengine失败
3.启动前请先将系统里运行的InfluxDB、TDengine停止下来,释放出这俩个数据库占用的端口,否则Docker container加载的时候会因为端口被占用了导致加载失败,从而无法完成测试。
在整个测试过程中,建议另开一个终端,运行top,查看系统的CPU和内存占用情况。
本测试包提供了一个run.sh脚本,自动执行将docker容器按指定IP地址运行起来,然后产生数据,写入数据文件,并写入时序数据库。 数据产生和写入由以下两条命令完成
#产生模拟数据并写入数据文件
bin/bulk_data_gen -seed 123-format influx-bulk -sampling-interval 1s-scale-var10-use-case devops -timestamp-start "2018-01-01T00:00:00Z"-timestamp-end"2018-01-02T00:00:00Z">data/influx.dat
bin/bulk_data_gen -seed 123-format tdengine -sampling-interval 1s-tdschema-file config/TDengineSchema.toml -scale-var10-use-case devops -timestamp-start "2018-01-01T00:00:00Z"-timestamp-end"2018-01-02T00:00:00Z"> data/tdengine.dat
解释一下以上的命令:按influxDB/TDengine的格式,以1秒一条数据的产生频率,模拟10台设备,以devops场景产生24小时的数据,并写入influx.dat文件。 Devops模型下,一台服务器会产生9类数据,分别是cpu,disk,mem,等,因此总共会产生7776000条数据记录。 数据文件完成后,就开始数据写入测试:
#数据写入数据库
cat data/influx.dat |bin/bulk_load_influx --batch-size=5000--workers=20--urls="http://172.15.1.5:8086"
cat data/tdengine.dat |bin/bulk_load_tdengine --url 172.15.1.6:0--batch-size 300-do-load -report-tags n1 -workers 20-fileout=false
上面命令的含义是以每批次写入5000/300条记录,分20个线程,将数据文件读取出来后写入influxDB/TDengine中
在完成写入后,就开始查询测试。 查询测试设定了四个查询用例的语句,每个查询语句都执行1000遍,然后统计总的查询用时:
测试用例1,
查询所有数据中,用8个hostname标签进行匹配,匹配出这8个hostname对应的模拟服务器CPU数据中的usage_user这个监控数据的最大值。
#TDengine
bin/bulk_query_gen -seed 123-format tdengine -query-type 8-host-all -scale-var10-queries 1000| bin/query_benchmarker_tdengine -urls="http://172.15.1.6:6020"-workers 50-print-interval 0
#InfluxDB
bin/bulk_query_gen -seed 123-format influx-http -query-type 8-host-all -scale-var10-queries 1000| bin/query_benchmarker_influxdb -urls="http://172.15.1.5:8086"-workers 50-print-interval 0
测试用例2,
查询所有数据中,用8个hostname标签进行匹配,匹配出这8个hostname对应的模拟服务器CPU数据中的usage_user这个监控数据,以1小时为粒度,查询每1小时的最大值。
#TDengine
bin/bulk_query_gen -seed 123-format tdengine -query-type 8-host-allbyhr -scale-var10-queries 1000| bin/query_benchmarker_tdengine -urls="http://172.15.1.6:6020"-workers 50-print-interval 0
#InfluxDB
bin/bulk_query_gen -seed 123-format influx-http -query-type 8-host-allbyhr -scale-var10-queries 1000| bin/query_benchmarker_influxdb -urls="http://172.15.1.5:8086"-workers 50-print-interval 0
测试用例3,
随机查询12个小时的数据,用8个hostname标签进行匹配,匹配出这8个hostname对应的模拟服务器CPU数据中的usage_user这个监控数据,以10分钟为粒度,查询每10分钟的最大值。
#TDengine
bin/bulk_query_gen -seed 123-format tdengine -query-type 8-host-12-hr -scale-var10-queries 1000| bin/query_benchmarker_tdengine -urls="http://172.15.1.6:6020"-workers 50-print-interval 0
#InfluxDB
bin/bulk_query_gen -seed 123-format influx-http -query-type 8-host-12-hr -scale-var10-queries 1000| bin/query_benchmarker_influxdb -urls="http://172.15.1.5:8086"-workers 50-print-interval 0
测试用例4,
随机查询1个小时的数据,用8个hostname标签进行匹配,匹配出这8个hostname对应的模拟服务器CPU数据中的usage_user这个监控数据,以1分钟为粒度,查询每1分钟的最大值。
#TDengine
bin/bulk_query_gen -seed 123-format tdengine -query-type 8-host-1-hr -scale-var10-queries 1000| bin/query_benchmarker_tdengine -urls="http://172.15.1.6:6020"-workers 50-print-interval 0
#InfluxDB
bin/bulk_query_gen -seed 123-format influx-http -query-type 8-host-1-hr -scale-var10-queries 1000| bin/query_benchmarker_influxdb -urls="http://172.15.1.5:8086"-workers 50-print-interval 0
查询过程结束后,将测试结果以以下格式打印出来
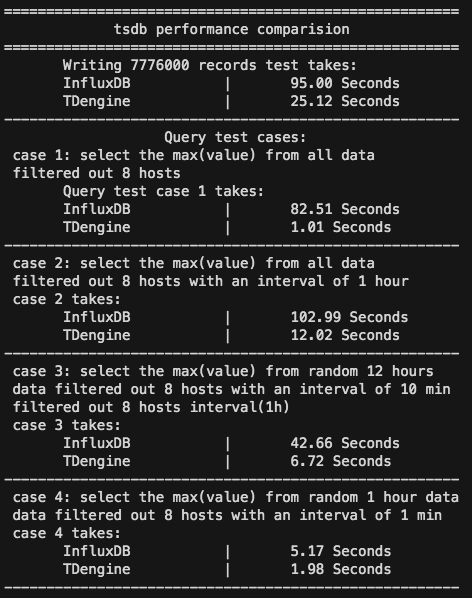
通过本测试包产生的数据和相关的写入、查询用例测试可以看出,TDengine在性能上相比InfluxDB有较大的优势。

细致分析下来可以有以下结论:
写入性能:相同数据源InfluxDB写入用时约是TDengine的4倍
全部数据聚合计算查询:InfluxDB查询用时约为TDengine的80倍
全部数据聚合计算查询以小时为颗粒聚合结果:InfluxDB查询用时约为TDengine的10倍
随机选取12小时的数据聚合计算查询以10分钟为颗粒聚合结果:InfluxDB用时约为TDengine的6倍
随机选取1小时的数据聚合计算查询以1分钟为颗粒聚合结果:InfluxDB用时约为TDengine的2.5倍
通过top命令的观察,我们可以看到,测试用例执行时,InfluxDB的CPU占用率基本达到满负荷,以4核CPU的服务器为例,经常达到390%以上;而TDengine的CPU占用率则低很多。
IoTDB 是清华大学主导的 Apache 孵化项目,是一款聚焦工业物联网、高性能轻量级的时序数据管理系统,提供数据采集、存储、分析的功能。IoTDB 提供端云一体化的解决方案,在云端,提供高性能的数
我们之前已经发布了 TDengine 和 InfluxDB 的写入性能测试报告,今天我们再来对比一下两款时序数据库(Time-Series Database)产品的查询性能。1. 前言本报告包含了基础
大家好。为了更好地展现 TDengine 的性能与竞争力,我们涛思数据精心策划了《 TDengine 和 InfluxDB 的性能对比》系列测试报告。该系列报告的主要测试点为:数据写入性能查询响应速度
Copyright © 2015 KnowSafe All rights reserved.
公司地址:成都市高新区天府大道北段1700号
业务邮箱:Sales@knowsafe.com
















