
社区精选 | Flowable 按角色分配任务
1. 用户与用户组
1.1 添加组
@Test
void test09() {
GroupEntityImpl g = new GroupEntityImpl();
g.setName("组长");
g.setId("leader");
g.setRevision(0);
identityService.saveGroup(g);
}

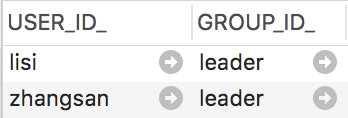
identityService.createMembership("zhangsan", "leader");
identityService.createMembership("lisi", "leader");
identityService.deleteMembership("zhangsan","leader");
1.2 修改组
Group g = identityService.createGroupQuery().groupId("leader").singleResult();
g.setName("主管");
identityService.saveGroup(g);
1.3 删除组
identityService.deleteGroup("leader");
1.4 查询组
//根据 id 查询组信息
Group g1 = identityService.createGroupQuery().groupId("leader").singleResult();
System.out.println("g1.getName() = " + g1.getName());
//根据 name 查询组信息
Group g2 = identityService.createGroupQuery().groupName("组长").singleResult();
System.out.println("g2.getId() = " + g2.getId());
//根据用户查询组信息(组里包含该用户)
List<Group> list = identityService.createGroupQuery().groupMember("zhangsan").list();
for (Group group : list) {
System.out.println("group.getName() = " + group.getName());
}
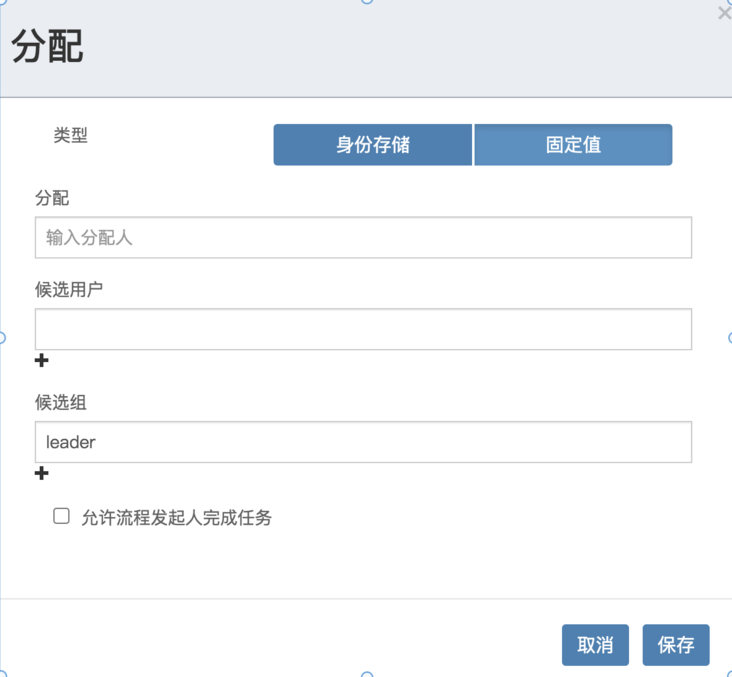
2. 设置候选组
<process id="demo01" name="测试流程" isExecutable="true">
<documentation>测试流程</documentation>
<startEvent id="startEvent1" flowable:formFieldValidation="true"></startEvent>
<userTask id="sid-F2F3C468-79B9-447B-943F-7CD18CE9BECF" flowable:candidateGroups="leader" flowable:formFieldValidation="true"></userTask>
<sequenceFlow id="sid-79C79920-2AD8-48FE-A59C-CC4D23C1895D" sourceRef="startEvent1" targetRef="sid-F2F3C468-79B9-447B-943F-7CD18CE9BECF"></sequenceFlow>
<endEvent id="sid-2236991E-3643-4590-9001-E22C256CA584"></endEvent>
<sequenceFlow id="sid-51105EB7-07F6-4190-9B2E-8F1F20A307D1" sourceRef="sid-F2F3C468-79B9-447B-943F-7CD18CE9BECF" targetRef="sid-2236991E-3643-4590-9001-E22C256CA584"></sequenceFlow>
</process>
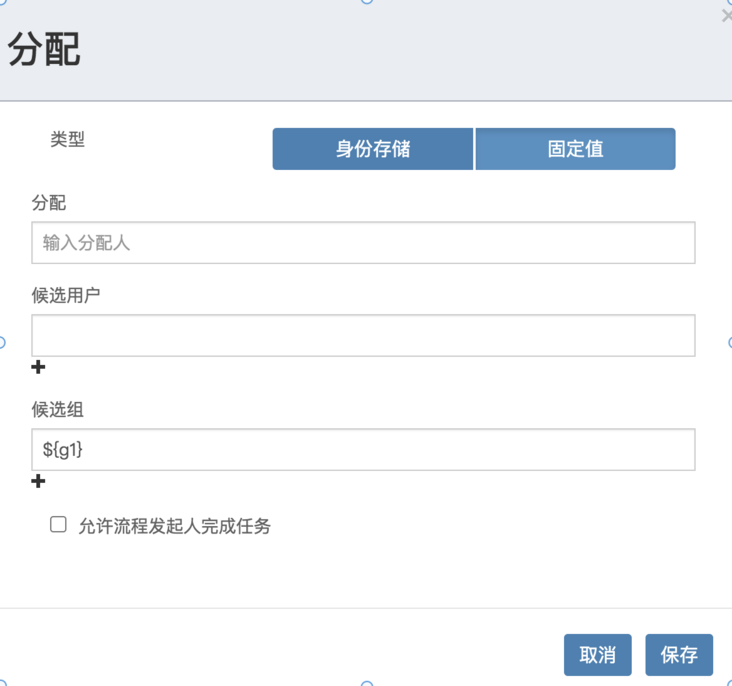
3. 根据用户组查询任务
@Test
void test01() {
Map<String, Object> variables = new HashMap<>();
variables.put("g1", "leader");
ProcessInstance pi = runtimeService.startProcessInstanceByKey("demo01",variables);
logger.info("id:{},activityId:{}", pi.getId(), pi.getActivityId());
}

@Test
void test19() {
List<Task> list = taskService.createTaskQuery().taskCandidateUser("zhangsan").list();
for (Task task : list) {
logger.info("name:{},createTime:{}", task.getName(), task.getCreateTime());
}
}
查询出来 zhangsan 是属于哪个 group,这个查询执行的 SQL 如下:
*SELECT RES.* from ACT_ID_GROUP RES WHERE exists(select 1 from ACT_ID_MEMBERSHIP M where M.GROUP_ID_ = RES.ID_ and M.USER_ID_ = ?) order by RES.ID_ asc*
查询 zhangsan 或者 leader 的任务,执行 SQL 如下:
SELECT RES.* from ACT_RU_TASK RES WHERE RES.ASSIGNEE_ is null and exists(select LINK.ID_ from ACT_RU_IDENTITYLINK LINK where LINK.TYPE_ = 'candidate' and LINK.TASK_ID_ = RES.ID_ and ( LINK.USER_ID_ = ? or ( LINK.GROUP_ID_ IN ( ? ) ) ) ) order by RES.ID_ asc
@Test
void test20() {
List<Task> list = taskService.createTaskQuery().taskCandidateGroup("leader").list();
for (Task task : list) {
logger.info("name:{},createTime:{}", task.getName(), task.getCreateTime());
}
}
SELECT RES.* from ACT_RU_TASK RES WHERE RES.ASSIGNEE_ is null and exists(select LINK.ID_ from ACT_RU_IDENTITYLINK LINK where LINK.TYPE_ = 'candidate' and LINK.TASK_ID_ = RES.ID_ and ( ( LINK.GROUP_ID_ IN ( ? ) ) ) ) order by RES.ID_ asc


关注公众号:拾黑(shiheibook)了解更多
赞助链接:
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
- 加币兑换人民币汇率2023年12月24日
- 日元对人民币汇率2023年7月16日
- 社区精选|万能的 CSS 渐变!单标签绘制一个足球场
- 汽车基础软件市场规模即将破百亿,谁会是中国“博世”?
- 【有料视频】省电模式会伤电池吗?
- 最新骗局!比杀猪盘更可怕的是"杀鸟盘"
- 日本内阁敲定78.9万亿日元规模经济对策
- 微信上线新功能,聊天信息可以加密了
- 美团饿了么回应《维护外卖送餐员权益指导意见》;网易云音乐回应上市 ;特斯拉发布2021年第二季度财报|Do早报
- 消灭打孔屏指日可待?三星再曝新专利
- 2021首款安卓新机发布:1500元内最强快充!
- 泡沫边缘疯狂试探,新能源汽车还值得投资吗?





 微信扫码关注公众号
微信扫码关注公众号