
前端架构师的 git 功力,你有几成火候?
大纲预览
分支管理策略 commit 规范与提交验证 误操作的撤回方案 Tag 与生产环境 永久杜绝 443 Timeout hook 实现部署? 终极应用: CI/CD
分支管理策略
Git Flow GitHub Flow GitLab Flow
dev-* develop staging release
dev-* 是一组开发分支的统称,包括个人分支,模块分支,修复分支等,团队开发人员在这组分支上进行开发。merge 合并 develop 分支的最新代码;开发完成后,必须通过 cherry-pick 合并回 develop 分支。develop 是一个单独分支,对应开发环境,保留最新的完整的开发代码。它只接受 cherry-pick 的合并,不允许使用 merge。staging 分支对应测试环境。当 develop 分支有更新并且准备发布测试时,staging 要通过 rebase 合并 develop 分支,然后将最新代码发布到测试服务器,供测试人员测试。release 则表示生产环境。release 分支的最新提交永远与线上生产环境代码保持同步,也就是说,release 分支是随时可发布的。release 分支通过 rebase 合并 staging 分支,然后将最新代码发布到生产服务器。develop -> (merge) -> dev-* dev-* -> (cherry-pick) -> develop develop -> (rebase) -> staging staging -> (rebase) -> release
为什么合并到 develop 必须用 cherry-pick?
dev-* 分支多而杂,直接 merge 到 develop 会产生错综复杂的分叉,难以理清提交进度。为什么合并到 staging/release 必须用 rebase?
commit 规范与提交验证
fix:,feat:,用来标记这个 commit 主要做了什么事情。build:表示构建,发布版本可用这个ci:更新 CI/CD 等自动化配置chore:杂项,其他更改docs:更新文档feat:常用,表示新增功能fix:常用:表示修复 bugperf:性能优化refactor:重构revert:代码回滚style:样式更改test:单元测试更改
npm install -g commitizen cz-conventional-changelog
~/.czrc 文件,写入如下内容:{ "path": "cz-conventional-changelog" }
git cz 命令来代替 git commit 命令,效果如下: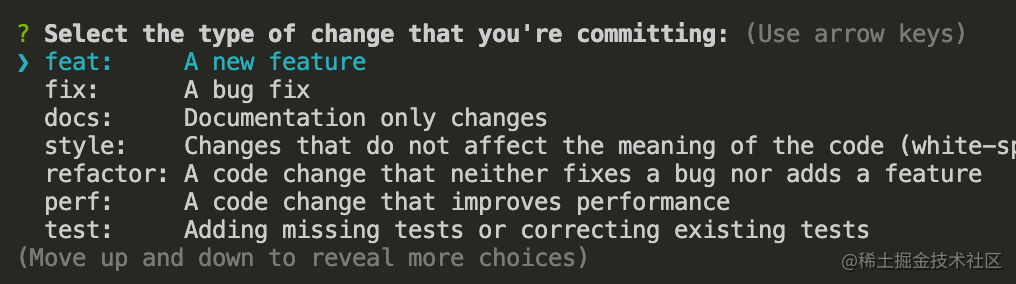
git hook,也就是 git 钩子。pre-commit:提交信息前运行,可检查暂存区的代码prepare-commit-msg:不常用commit-msg:非常重要,检查提交信息就用这个钩子post-commit:提交完成后运行
pre-receive:非常重要,推送前的各种检查都在这post-receive:不常用update:不常用
commit-msg 钩子在客户端对 commit 信息做校验。husky + commitlint误操作的撤回方案
reset 和 revertgit reset
commitId 来恢复版本。因为每次提交都会生成一个 commitId,所以说 reset 可以帮你恢复到历史的任何一个版本。$ git reset [option] [commitId]
$ git reset --hard cc7b5be
git log 命令查看提交记录,可以看到 commitId 值,这个值很长,我们取前 7 位即可。--hard,其实共有 3 个值,具体含义如下:--hard:撤销 commit,撤销 add,删除工作区改动代码--mixed:默认参数。撤销 commit,撤销 add,还原工作区改动代码--soft:撤销 commit,不撤销 add,还原工作区改动代码
--hard,使用这个参数恢复会删除工作区代码。也就是说,如果你的项目中有未提交的代码,使用该参数会直接删除掉,不可恢复,慎重啊!$ git reset --soft HEAD^
HEAD^ 表示上一个提交,可多次使用。# 1. 回退到上次提交
$ git reset HEAD^
# 2. 修改代码...
...
# 3. 加入暂存
$ git add .
# 4. 重新提交
$ git commit -m 'fix: ***'
$ git commit --amend
git add,然后再执行这个命令,比上述的流程更快捷更方便。-f 参数,强制推送,这时本地代码会覆盖远程代码。-f 参数非常危险!如果你对 git 原理和命令行不是非常熟悉,切记不要用这个参数。git revertgit revert
-f 参数的问题,提高了安全性。$ git revert -n [commitId]
Tag 与生产环境
v1.2.4 的版本:$ git tag -a v1.2.4 -m "my version 1.2.4"
$ git show v1.2.4
> tag v1.2.4
Tagger: ruims <2218466341@qq.com>
Date: Sun Sep 26 10:24:30 2021 +0800
my version 1.2.4
$ git push origin v1.2.4
git reset,git revert 命令。$ git revert [pre-tag]
# 若上一个版本是 v1.2.3,则:
$ git revert v1.2.3
永久杜绝 443 Timeout
https 协议,还支持 ssh 协议。于是准备尝试一下使用 ssh 协议克隆代码。$ git clone git@github.com:[organi-name]/[project-name]
hook 实现部署?
终极应用: CI/CD


关注公众号:拾黑(shiheibook)了解更多
赞助链接:
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
- AppNode如何设置http自动跳转到https?
- 美国防部发布《数据、分析和人工智能采用战略》
- 营收连续四个季度下滑,生成式AI初现苹果蓝图
- 英镑兑人民币2023年5月7日
- 反「PPT骗子」,互联网大厂是认真的吗?
- 乔布斯编号电脑预计成交价 265 万元 ;开源软件托管商 Fosshost CEO 失联|思否周刊
- 广东发布硅能源产业发展行动计划,2025年产业规模达2000亿元
- 【大公司创新情报】中国GPU芯片公司摩尔线程完成A轮20亿元融资,腾讯、字节参投
- 这些交易,触目惊心!数十亿条个人信息明码标价售卖
- 统信“第一课”:学党史 干实事 开新局 ,践行初心使命勇担时代重任
- 米聊关停了,变身“中国版Clubhouse”又回来了?
- 美国参议员团体要求美国商务部继续向华为施压
赞助链接





 微信扫码关注公众号
微信扫码关注公众号